如何优化 ChatGPT 生成的草稿,去除 AI 味
如何在写作中识别并去除“AI 废话”
如果你想利用大语言模型(LLM)提高写作速度,又不想让文章读起来像机器写的,这篇文章就是为你准备的。在 Towards AI,过去两年里我们编辑了数千份 AI 辅助的稿件,制作了数百节课程和视频。我们清楚地知道模型在哪里能帮上忙,在哪里会帮倒忙,以及如何保持你自己的声音。在这篇文章中,我们将分享一些具体的技巧和一个经过实战检验的提示词模板。通过这些,你可以从 LLM 那里获得高质量的文本,同时避开 AI 生成文章的典型特征——而不仅仅是双手合十,温柔地请求它“请不要写得像 ChatGPT”。
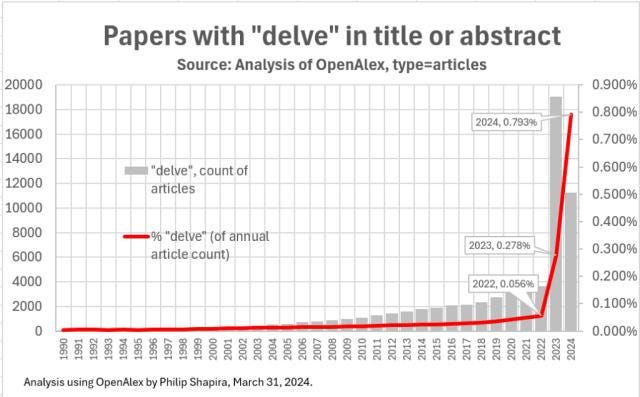
在 2023 年和 2024 年,某些动词和形容词突然开始在各类稿件和出版物中泛滥:深入探讨 (delve)、领域 (realm)、凸显 (underscore)、一丝不苟 (meticulous)、值得称赞 (commendable),还有著名的破折号 (em-dash)。在 ChatGPT 出现之前,许多专业编辑除了在正式报告中,几乎很少见到这些词;如今,它们却充斥在学生论文、电子邮件、内部备忘录、领英动态和生物医学论文中。一项评估发现,与 2022 年底之前相比,“delve” 这一个词在近期 PubMed 文章中出现的频率大约增加了 400%。在学术界之外,一项被广泛引用的在线文本分析发现,与前几年相比,生成式 AI 时代的“meticulously researched(经过精心研究)”一词的使用频率增加了约 3900%。
所以,大家的直觉是对的:模型不仅改变了我们起草文本的方式,还正在肉眼可见地改变我们周围的语言环境。LLM 在海量的文本语料库上进行训练,然后通过基于人类反馈的强化学习 (RLHF) 进行打磨,学会迎合我们的需求。最近的一篇语言学论文找出了 21 个在科学论文摘要中使用频率激增的“焦点词”,并且 ChatGPT 使用它们的频率远高于人类作者;作者给出的最佳解释是,RLHF 悄悄地引导模型偏向那些疲惫的评分员视为“好文章”标志的词语。记者和语言学家进一步指出,由于 RLHF 工作被大量外包给尼日利亚等国家的英语熟练标注员,其中一些词可能反映了正式的尼日利亚英语习惯,这些习惯被反复奖励,然后在互联网规模上被放大。
一旦这种风格被固化,数百万人就开始复制并稍作修改地使用它。久而久之,这种经过打磨的、客气且带有学术腔调的模型语气,就会渗透到 AI 辅助甚至纯人类撰写的文本中。即使你从未打开过 ChatGPT,你最终也会生活在一个充斥着“深入探讨 (delve into)”、“凸显 (underscore)”、“不断演变的格局 (ever-evolving landscape)”和“无缝、稳健的解决方案 (seamless, robust solutions)”的信息环境中。
这就是我们可以称之为 AI 废话 (AI slop) 的东西:不仅是几个可疑的词,而是一套让文章感觉不自然的习惯。尴尬的是,即使最明显的“AI 词汇”被删除了,那种感觉往往依然存在。这种感觉很难用清晰的语言来描述。然而,大多数读者都能分辨出一篇文章是由 LLM 撰写的,还是经过其大量“润色”的。表面的词汇被清理了;但底层的骨架依然没变。段落仍然遵循着相同工整的弧线,过渡句像五段论式文章一样按部就班,结论总是拔高到一个没人要求的“更大图景”。语言中没了 delve,但思维结构仍然是纯粹的模型味。
因此,如果你希望 AI 辅助写作不感觉像是 AI 废话的拼凑,你不能仅仅删掉 delve;你必须改变骨架。下一节将首先探讨这个骨架:LLM 默认情况下倾向于如何组织想法,以及你可以在大纲、段落和过渡中做哪些调整,从而在一篇文章还未触及具体词汇之前,就不再读起来像个 AI 模板。
优化结构
当人们说“这听起来像 ChatGPT”时,他们通常是在对结构做出反应,而不仅仅是词汇选择。句子单独看没问题,但它们的排列方式让人觉得通用且过于熟悉。总觉得哪里不对劲。
常见的结构模式包括:
- 大量使用项目符号列表: 文章的大部分都是简短的要点,而不是带有例子或细节的完整段落。
- 大量相似的小标题: 每隔几段就有一个诸如“理解 X”、“Y 的重要性”、“Z 的未来”这样的标题。各个部分感觉可以互换。
- 标准的文章框架: 宣告主题的概括性开头,三个呼应开头的正文部分,最后是一个重申每个标题的总结。
- 到处都是强烈的路标提示: 经常出现类似“现在我们已经探讨了 X……”、“如前所述……”、“在下一节中,我们将讨论……”这样的句子,即使逻辑联系已经很明显。
- 段落长度一致: 大多数段落长度相似,并遵循相同的模式:定义、解释、限定条件、小结。节奏几乎没有变化。
- 围绕文章本身写作,而不是主题: “在本节中,我们将看看……”、“首先,我们将检查……然后我们将探索……”。
- 通用且过度简化的例子:“例如,企业可以使用 AI 来简化工作流程并改善结果。” 这种例子在技术上是正确的,但过于通用,没有提供任何新信息。它几乎可以出现在任何关于 AI 的文章中,这正是读者能认出它是机器生成的原因。
- 通用的结论: 最后的段落总是拔高到一个安全的、高层次的陈述(“随着 AI 的不断发展……”),而没有增加任何具体内容。
单独来看,这些在很大程度上都没问题。它们对于学校论文、文档和操作指南博客很有用。问题在于,当所有这些都同时出现,并且无论什么主题都按同样的顺序排列时。到了那个时候,文章就不再感觉像是一个人的真实推理,而开始感觉像是一个被重复使用(甚至滥用)的框架。
LLM 之所以陷入这种模式,是因为它们的训练数据中充满了这种模式:教科书、教程、企业说明文、学生论文。当你要求“写一篇关于 X 的文章”时,模型并不是在优化一个有趣的结构;它是在寻找“安全的文章结构”,并把你的主题塞进去。
如果你想保持 AI 的速度,又不要那种模板感,你必须在这个层面做出改变:大纲、段落形状和过渡。
一条有用的规则是:你掌控结构;模型负责填充。 这里有一些实用的改变方法:
1. 自己决定大纲
在开始写提示词之前,自己先草拟一个简短的大纲:从哪里开始,哪些部分最重要,在哪里结束。让某些部分短一些,有些部分长一些;它们不需要是对称的。
然后要求模型类似这样:
“把这个大纲变成文章。不要在这些内容之外添加引言或结论。不要创建额外的小标题。”
你这是在告诉它留在你的框架内,而不是自己发明一个。
2. 偏好段落而不是列表
LLM 过度使用项目符号和标题,因为许多在线内容就是这样构建的。如果你想要读起来更像文章而不是幻灯片的内容,你必须明确指出。
你可以添加一个简单的约束:
“主要使用完整的句子和结构良好的段落进行写作。避免使用列表或项目符号,除非内容明确需要(例如,具体的步骤或不同的项目)。少用小标题,只在明显不同的部分使用,不要为每一个新想法都加个标题。”
这会促使模型走向连续的叙述:更饱满的段落、更流畅的过渡,以及更少列表状的碎片。如果你真的需要,以后总可以把其中一部分变回列表。
3. 限制类比,不让它们主导结构
模型也喜欢依赖类比,以此作为一种显得通俗易懂的捷径。太多或牵强的类比会让人觉得文章注水、重点模糊。
你可以用一条简短的规则来控制它们:
“极少使用类比,只有当它们能为这类读者提供真实的、非显而易见的澄清时才使用。除非我明确要求更多,否则整篇文章最多使用一个类比。”
这能让结构锚定在实际的论述上,而不是模型在其他文章中看过的一串隐喻上。
4. 减少元文本和路标
在提示词中,限制“在这一节中我们将……”这种风格:
“避免使用类似‘在这一节中,我们将……’、‘现在我们已经探讨了……’、‘如前所述……’这样的短语。不要描述文章本身;只需解释主题。避免使用没有附加值的废话。”
在审阅草稿时,快速扫一遍这些元文本,删掉那些清嗓子式的开场白、重复标题的总结句,以及任何只是重述读者已知内容的结尾段落。
5. 打破对称性
告诉模型:
“改变段落长度。有些部分可以很短;有些可以深入。不要在每节的结尾都加上一个小总结。”
如果草稿仍然有三个结构相等、标题相似的部分,那就手动修复:合并重叠的部分,将较弱的标题降级为普通段落,或者完全删掉某一部分。一旦大纲不再像一篇整齐的三段式论文,这篇文章读起来就不那么像默认的 AI 输出了。
6. 将 AI 作为积木,而不是现成的段落
不要说“写第二节”,而是使用模型来生成组件:
- “给我三种不同的方式来组织这一节。”
- “列出具体的例子,使这个论点更加具体”,或者更好的是,“我想用攀岩世界来做一个类比,因为我认为这有助于读者把事情串联起来,帮我想一个合适的。”
- “在这些段落之间建议两个不复述刚才读过内容的过渡。”
然后由你来选择、重新排序并连接。模型给你提供材料;你来决定它们的流向。
7. 在修改语言之前,先过一遍结构
在你修改句子之前,将每段变成一句话的总结。像看大纲一样读这些句子。它听起来像你写的,还是像一篇通用的博客文章:定义 → 列表 → 总结 → 模糊的未来?
如果是后者,重新排序、删减或精简,直到顺序与你大声解释这个主题的方式相匹配。通常,删掉第一段、精简总结,并在前一步就结束,就足以消除大部分的“AI 感”。
一旦结构是你的了,草稿就已经不那么像模型了,即使它是 AI 生成的。在那之后,你就可以专注于语言:屏蔽你自己的“AI 词汇”列表,收紧措辞,并使用一个去 AI 味提示词,让模型一开始就不再使用那些相同的词汇。
你可以添加到提示词中的语言规则
一旦结构没问题了,剩下的大部分“AI 感”来自于句子层面的习惯:重复、通用的开头和结尾、含糊的形容词、过于客气的语气,以及反复出现的一组“AI 词汇”。你可以将这些变成提示词中明确的规则,这样初稿就已经避开了大部分问题。
- 重复
AI 的一个常见标志是看似无害的重复,这使文本感觉机械化:几个句子或段落以相同的方式开头,或者一遍又一遍地使用相同的节奏。
提示词规则:
“改变句子开头。避免多次重复相同的过渡词(‘此外 (In addition)’、‘而且 (Furthermore)’、‘再者 (Moreover)’)。不要用不同的词重述同一个想法。”
编辑检查:只看开头读一遍。忽略意思,只看每个句子的前几个词。只要你看到相同的开头或模式出现三次,就删减或合并。通常,两个模型的句子可以合并成一个更清晰的句子,而不会丢失内容。
- 开头和结尾
通用的引言和结论是另一个明显的标志。它们宣布文章将要做什么,然后在结尾重复一遍。
提示词规则:
“不要以‘在当今快节奏的世界中’或‘当我们应对复杂性时’等通用的场景设置开头。以具体的例子、具体的声明或明确的问题开头。不要以‘总之 (In conclusion)’或对各节的回顾结束。在论点或解释自然结束的地方结束。”
编辑检查:如果第一段稍加修改就能用在另一篇文章上,那就删掉或重写它。如果最后一段只是重复读者已经知道的内容,那就删除它,或者用一个具体的结束句来代替。
- 形容词
模型经常依赖积极但含糊的形容词:强大的 (robust)、无缝的 (seamless)、开创性的 (groundbreaking)、变革性的 (transformative)、关键的 (pivotal)、引人入胜的 (intriguing)、创新的 (innovative)、全面的 (comprehensive)。它们听起来很自信,但没有增加任何信息。
提示词规则:
“避免使用含糊或戏剧性的形容词,如‘强大的 (robust)’、‘无缝的 (seamless)’、‘关键的 (pivotal)’、‘开创性的 (groundbreaking)’、‘变革性的 (transformative)’、‘引人入胜的 (intriguing)’、‘创新的 (innovative)’、‘全面的 (comprehensive)’。只有当形容词增加了具体信息(例如关于规模、性能或限制)时才使用它。否则,将其删除。”
编辑检查:拿一段话,去掉所有的形容词。然后,只放回那些以有用方式改变意思的词。用细节代替情绪:“强大的系统 (robust system)”可以变成“每秒处理 1 万个请求且不丢失数据的服务”。
- 客气
因为模型被训练成安全和不冒犯他人,所以它们默认使用非常礼貌、正式的措辞:“希望这封邮件找到你时你一切都好 (I hope this email finds you well…)”、“我想花点时间来 (I would like to take a moment to…)”、“我谦卑地请求 (I humbly request…)”。
提示词规则:
“用直接、中立的专业语气写作。避免使用老套的电子邮件用语,如‘希望这封邮件找到你时你一切都好’或‘我想花点时间表达我诚挚的感激之情’。在第一句话就切入正题。避免使用软化词,如‘只是 (just)’、‘我想知道是否 (I was wondering if)’、‘希望 (hopefully)’,除非它们对于人际关系是必不可少的。”
编辑检查:问自己“我会大声说出来吗?”如果不,就精简它,直到你可以。“我想友好地跟进一下关于……”通常会变成“只是了解一下关于……”或“有什么进展吗?”。
- 词汇黑名单
有些词和短语现在读起来就像是标准的 AI 输出:深入探讨 (delve)、领域 (realm)、挂毯 (tapestry)、不断演变的格局 (ever-evolving landscape)、想象 (imagine)、踏上旅程 (embark on a journey)、导航/应对 (navigate,作为隐喻)、利用 (leverage)、驾驭/利用 (harness)、努力 (endeavour)、充满活力的 (vibrant)、至关重要的 (crucial)、令人信服的 (compelling)、“不仅是 X,而且是 Y”。
没有通用的清单;不同的领域有不同的习惯。保留一个小清单,列出你不想看到的词,除非你是故意选择它们的。
提示词规则:
“不要使用以下词语:深入探讨 (delve)、踏上 (embark)、想象 (imagine)、领域 (realm)、挂毯 (tapestry)、充满活力的 (vibrant)、努力 (endeavour)、利用 (leverage)、驾驭 (harness)、应对/导航 (navigate,作为隐喻)、无缝地 (seamlessly)、关键的 (pivotal)、开创性的 (groundbreaking)、变革性的 (transformative)、令人信服的 (compelling)、不断演变的 (ever-evolving)、范式 (paradigm)、‘释放潜力 (unlock the potential)’。如果你通常会伸手去拿其中一个,请选择一个更简单的动词或具体的描述代替。”
随着新的模式开始困扰你,随着时间推移更新这个清单。
- 忠实度和确定性
当模型根据笔记、文字记录或源文章工作时,它需要明确的界限。
提示词规则:
“当提供上下文或源文本时,要忠实于它。不要比原文添加或暗示更多的信心或确定性。如果一个事实不在来源中,要么省略它,要么将其标记为不确定。根据上下文,将课程内容称为‘课程 (lesson)’,将独立文章称为‘文章 (article)’。”
- 语气和视角
你想要的是一致性,而不是表演。
提示词规则:
“通过具体的细节和清晰的推理,而不是戏剧效果或额外的修饰,使文章具有可读性和趣味性。在整个过程中保持单一、一致的语气和视角(选择‘我们 (we)’或‘你 (you)’并坚持下去)。不要在同一篇文章中混合使用‘我 (I)’、‘我们’和‘你’。对于教学内容,默认使用‘我们’。”
- 直接、清晰、简洁
修辞手法和重复的定义是废话悄悄溜回来的常见方式。
提示词规则:
“直接了当。避免废话和对话式的填充。不要问一个问题然后立即自己回答作为一种手段(例如:‘那么,X 到底是什么?’)。直接陈述观点或定义。
每句话都应添加新信息或细微差别。避免用不同的词重复同一个观点。不要在同一文档或系列中多次重新定义相同的首字母缩略词或概念。如果删除一个句子不会改变读者的理解,那就省略它。”
一个可复用的去 AI 味提示词
这里是经过修改的版本,变化很小,只是插入了新的规则。
你正在帮助我起草高质量、不敷衍且带有人类口吻的文章。
[1] 任务与背景
- 撰写一篇关于:[主题] 的 [格式:文章 / 章节 / 电子邮件 / 脚本 / 等]。
- 背景:[本文将被用在哪里,以及为什么要写]。
- 使用以下来源材料作为事实基础。不要与之矛盾:
[粘贴笔记、大纲、引言、链接]。
[2] 受众与目标
- 受众:[他们是谁:角色、对主题的熟悉程度、限制]。
- 假设他们已经知道:[不要过度解释的内容]。
- 阅读后,他们应该能够:[1-3 个具体结果]。
[3] 结构
- 遵循以下结构:
- [第一节名称 + 1-2 行关于它涵盖的内容]
- [第二节...]
- [第三节...]
- 不要在此大纲之外添加额外的章节。
- 使用完整的段落;每段集中于一个清晰的观点。
- 仅对真正独立的项目(步骤、优缺点等)使用项目符号列表。
- 谨慎使用小标题;不要为每个段落创建标题。
- 保持标题简短而基于事实。不要使用戏剧性或叙述性的两部分标题。
- 确保章节之间过渡平滑自然,不要使用类似“现在我们探索了 X,让我们转向 Y”的元陈述。
[4] 风格与语调
- 清晰、中性的散文:专业,但在有助于理解的地方可以稍微带点俏皮和机智。
- 通过具体的洞察和清晰的推理使文章具有可读性和吸引力,而不是靠戏剧性或额外的渲染。
- 避免戏剧化、炒作、流行语和营销式的语言。
- 避免辞藻华丽的散文(没有华丽、夸张或令人窒息的语言)。
- 使用一致的视角(“我们”或“你”)并坚持下去。
- 直接。避免填充词和口语化的废话。
- 不要以自问自答作为诱饵;直接陈述观点。
- 使用完整的句子;不要将句子片段作为一种文体手段。
- 不要使用破折号(—)。使用逗号或句号代替。
[可选的声音匹配]
- 匹配此示例的节奏、句子长度和语调:
[粘贴 1-2 段我自己写的文章]。
[5] 语言与词汇限制(去 AI 味)
- 避免使用通用的文章和博客短语,例如:
“在当今快节奏的世界中……”、“当我们应对复杂性时……”、“总而言之……”。
- 不要使用以下句子结构:
- “这不仅是 X,更是 Y。”
- “X 不仅是 Y;它还是 Z。”
- “这不是 X,而是 Y。”
- “这就是 X 发挥作用的地方。”
- 除非我在输入中明确包含,否则不要使用这些词/短语:
惊人的 (amazing)、迷人的 (fascinating)、令人惊叹的 (mind-blowing)、必读的 (must-read)、快速发展的世界 (fast-moving world)、拨开迷雾/噪音 (cut through the hype/noise)、开创性的 (groundbreaking)、范式转变的 (paradigm-shifting)、变革性的 (transformative)、关键的 (pivotal)、至高无上的 (paramount)、杰出的 (outstanding)、一个重大飞跃 (a significant leap)、深入研究 (delve, dive into)、着手/开始 (embark/embarking)、努力 (endeavour)、领域 (realm)、织锦 (tapestry)、充满活力的 (vibrant)、利用 (leverage)、驾驭 (harness)、无缝集成 (seamlessly integrates)、从头开始 (start from the ground up)、解决一个新颖的问题 (tackle a novel problem)、至关重要的 (crucial, critical)、无价的 (invaluable)、显著的/地 (significant/significantly)、令人惊讶地 (surprisingly)、简单地 (simply)、巧妙地 (neatly)、“最棒的是” (“the best part is”)、“真正的奇迹发生” (“real magic happens”)、“灾难的秘诀” (“recipe for disaster”)、“繁荣” (“thrive”)、“释放真正的力量” (“unlock the real power”)。
- 优先使用平实、具体的动词和特定的技术术语,而不是模糊或戏剧性的措辞。
- 仅在添加具体信息(规模、约束、性能)时才使用形容词。
- 极少使用类比,只有当它们提供非显而易见的澄清时才使用。
不要使用引导性的类比短语,如“想象……”或“把这想成……”。
[6] 准确性与术语
- 忠实于提供的上下文和来源。
- 不要夸大确定性;如果事实不确定,要么省略它,要么将其标记为不确定。
- 对于首字母缩略词,在首次使用时写出完整短语,然后使用缩略词。
“AI”和“LLM/LLMs”可以在不展开的情况下使用,除非受众完全是新手。
- 根据需要,将“课程 (lesson)”用于课程内容,将“文章 (article)”用于独立文章。
[7] 流程
- 首先,对照上述规则默默检查你自己的输出。
- 删除重复的句子开头、禁用的词语和不添加新信息的填充句。
- 不要在最终输出中包含内部评论、给自己留的便条或占位符。
答案读起来应该是一个完整、打磨过的产品。
- 然后呈现最终草稿,不解释你做了哪些修改。
这个模块可以放在你更大的通用模板(包含任务、受众、结构和准确性)中。对于电子邮件,你可能会保留客气规则并精简其余部分。对于长篇文章,你可能会保留所有内容,并用特定领域的陈词滥调扩展黑名单。
关键点在于,你不再需要每次都重新发明“请不要听起来像 ChatGPT”了。你只需决定一次你希望语言如何表现;模型会将其作为它工作描述的一部分来读取。
AI 修改循环在实践中是什么样的
即使有很好的结构和经过仔细推敲的提示词,大多数模型在第一次尝试时也不会遵循所有规则。它们仍然会偷偷混入一个“快节奏的世界”,三次重复使用相同的过渡,或者又退回到散文式的结论。这是正常的。目标不是一次性获得完美的草稿;而是建立一个循环,让模型在你花费大量编辑时间之前完成大部分清理工作。
一个有用的思考方式是:第一个回复是版本 0,而不是你必须接受的草稿。你首先使用完整的模板要求内容和结构:任务、受众、大纲以及你的去 AI 味语言规则。版本 0 应该有大致正确顺序和正确的想法。如果结构不对,你要先修复它;在你打算删减或移动的段落上打磨语言是毫无意义的。
一旦结构没问题了,你就让 LLM 充当法官。在实践中,这通常意味着打开第二个聊天窗口或使用不同的模型。第一个聊天是你产生草稿的“作家”模型。第二个聊天/模型是你的“编辑”模型,其唯一工作是查找并标记废话。你把草稿和规则粘贴进去,并要求它只审阅,不重写。例如:
“你正在审阅一份草稿,寻找 AI 废话和风格问题,而不是重写它。
这是我们使用的规则(结构和语言):
[粘贴你的大纲约束 + 去 AI 味模块]
这是草稿:
[粘贴草稿]
1. 指出这份草稿在哪里违反了上述规则:
- 重复的开头或过渡
- 通用的引言或结论
- 含糊或夸张的形容词
- 老套的电子邮件短语或过度客气
- 黑名单中的 AI 常用词
2. 对于每个问题,用一句简短的话建议如何修复它。
暂时不要重写整篇文章。”
将该回复视为诊断。它通常会突出显示通用的开头、重复的模式、残余的禁用词以及读起来像总结的段落。你现在有了一个具体的问题列表,而不必自己通读全文。
接下来,你回到作家窗口,并要求进行第二遍修改,将编辑的笔记作为输入。你不想要一篇全新的文章;你想要一个保留了结构和想法但修复了问题的修改版。这样的提示词可能看起来像这样:
“这是你的初稿,加上一份指出了它在哪里违反了我们商定的风格/去 AI 味规则的审阅。
[粘贴审阅意见]
重写草稿,只修复这些问题:
- 删除通用的引言和散文式的结论
- 改变重复的句子开头
- 删除或替换含糊的形容词和 AI 常用词
- 删除元文本(“在这一节中我们将……”)和沉重的路标提示
保持结构、章节和主要论点不变。”
如果某个部分特别糟糕,你可以把它隔离出来,一次只做这块。这样可以防止模型“乐于助人”地重新引入你刚刚在文章其他部分删除的模式。
一旦“作家”和“编辑”模型完成了它们的检查,你可以在此基础上添加几个简单的步骤。
使用外部检查器作为第二意见
一个选项是通过 Slop Score 运行修改后的草稿,这会让你了解短语模式看起来有多“GPT”。另一个是 Creative Writing Longform benchmark,它侧重于更长、更像人类的文本。这些工具不会替你做决定,但它们是有用的信号。如果分数飙升,或者某些短语被挑出来认为高度类似模型生成的,你可以将此反馈到你的流程中:将这些模式添加到你的黑名单中,或者要求第二个窗口中的编辑模型下次明确查找它们。
让人类编辑保持专注
一旦模型和工具完成了它们的工作,你就可以进行一次简短、专注的人类编辑。在这里,你为了结构而读,询问段落顺序是否真正匹配你大声解释主题的方式。你为了准确性而读,检查数字、名称和声明是否基于你认可的来源或知识。你为了质感而读,注意文章听起来像你或你的团队,还是像一个没有明确作者的通用说明文。在这个阶段你注意到的任何新的口头禅或模式,都可以直接加入你的黑名单,这样它们就不会在未来的草稿中再次出现。至关重要的是,你要补充你在阅读时想到的例子或见解,为文章增添你的个性和触感。
以版本的概念思考,而不是单一草稿
在实际工作流中,这通常意味着进行两三次快速循环,而不是产生一篇大而完美的草稿。版本 0 是你使用主要提示词将内容和大致结构落实到位的地方。版本 1 是模型根据你的规则对其自身进行批评和修改后的草稿,可能借助了 Slop Score 或 longform benchmark。版本 2 是你编辑过的版本,你在这里调整判断、细微差别和语气。提示词模板、黑名单、编辑窗口和外部工具的存在,都是为了让这些循环变得更廉价,让“AI 草稿”的含义从“我必须从头重写的东西”变成“我只需要稍微编辑一下的东西”。
为什么人类的审视依然重要
所有这些都无法消除人类审阅的必要性。模型可以根据你的规则起草、重组和修改,但它们仍然无法决定哪些观点对你的读者重要、你对某个声明应该有多大的把握,或者文章听起来是否属于你的声音。检查结构、事实和语气仍然是你的工作。
让这项工作变得可管理的办法是标准化工作流。你重复使用同一个基础提示词,而不是每次都写新的指令。你保留一个小黑名单,并在新的“AI 词”出现时更新它。你在第二个聊天中使用固定的编辑提示词,这样模型就可以在你编辑之前标记出它自己的习惯。你最后的检查就会遵循一个简单的清单:结构合理,声明有依据,语言符合你或你团队的惯常写作方式。
如果你坚持这样做,AI 并不会消除编辑工作,但它确实改变了你所做编辑的种类。大部分机械的废话由模型和你的提示词处理。你的时间花在了只有你能做出的决定上:你想说什么、你愿意在一个声明上走多远,以及这是否是一篇你乐意署名的文章。